# Install librarian (if you need to)
# install.packages("librarian")
# Install (if not already present) and load needed libraries
librarian::shelf(vegan, RRPP, scatterplot3d, TeachingDemos, supportR)Multivariate Statistics 101
Caveat Before We Begin
- Read this book
- Has a complete R appendix for:
- Every example
- Every figure
- Every operation
- Essentially the book is written in R Markdown
- Bonus: actually pretty engaging to read!
- Despite subject matter

Resampling Methods
- Frequentist statistics uses distributions from theory

- Resampling statistics uses distributions from data
Two Major “Flavors”
Full Permutation
- Permute whole dataset
Residual Permutation
- Fit desired model
- Permute the residuals
- Less sensitive to outliers

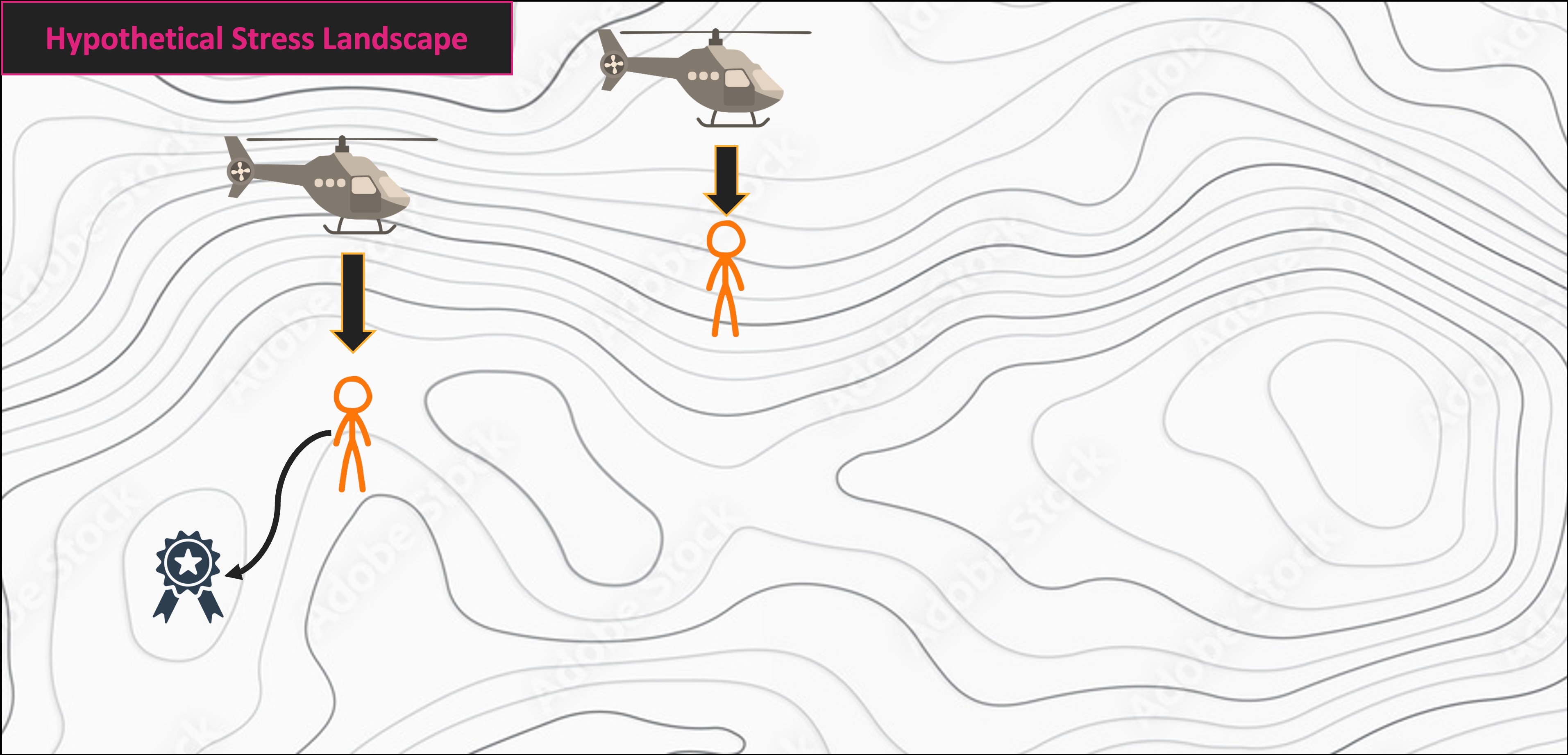
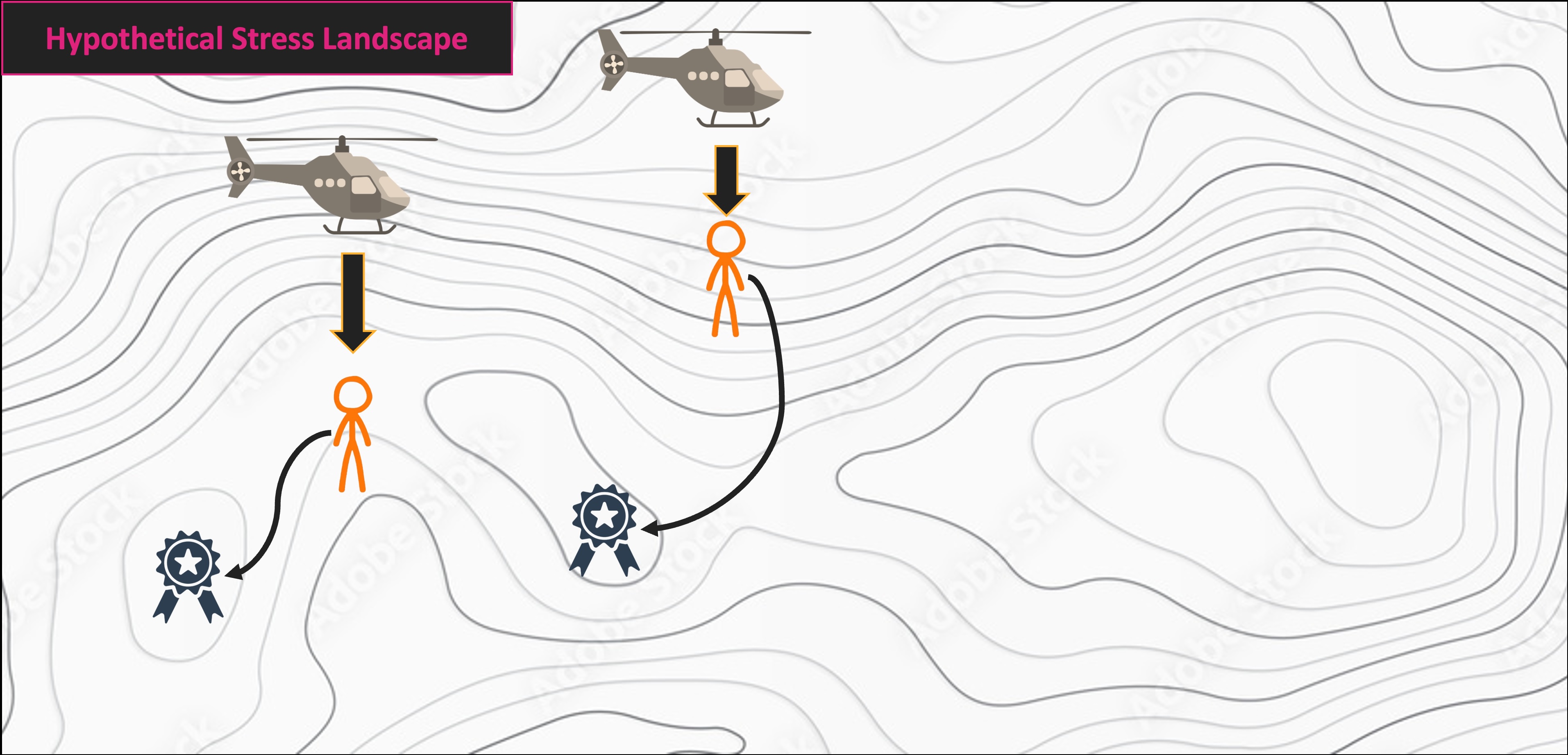
NMS Helicopter Analogy





3D Scatterplot
- Perhaps the simplest mode of multivariate data visualization is just to make a 3D scatterplot!
- Still technically counts as “multivariate” visualization
- Primary benefit is that interpretation is pretty straightforward
# Make 3D scatterplot with `scatterplot3d` library
scatterplot3d::scatterplot3d(lichen_df$Callvulg, lichen_df$Empenigr, lichen_df$Rhodtome,
xlab = "Callvulg", ylab = "Empenigr", zlab = "Rhodtome")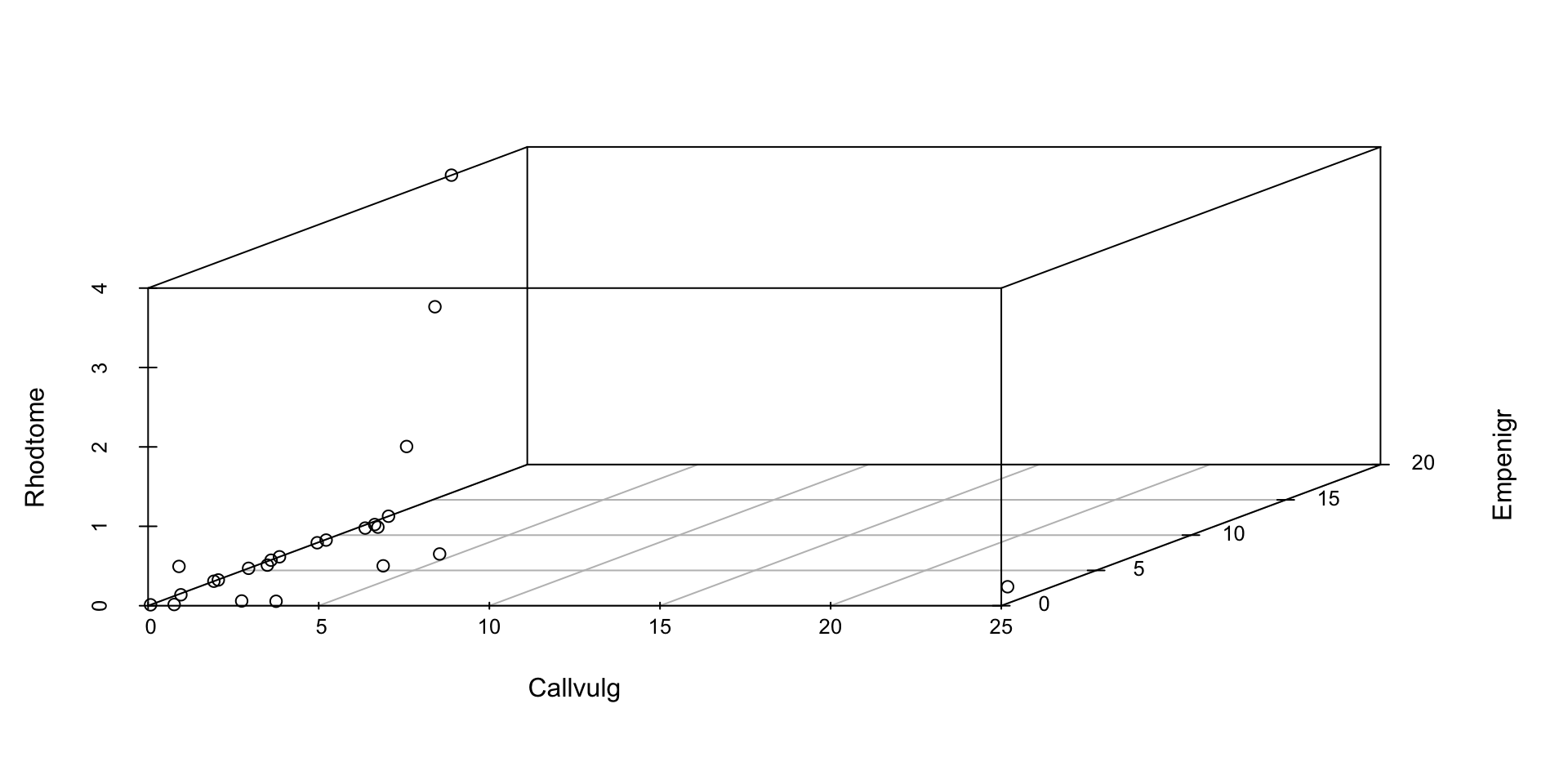
Chernoff Faces
- Some people have tried to make human’s capacity for comparing faces into a tool for data visualization
- Data are transformed into human(-ish) faces with different dimensions
- I find these very scary
# Make a matrix out of your desired data
lich_mat <- data.matrix(varespec)
# Generate Chernoff face graph
TeachingDemos::faces2(lich_mat, labels = lichen_df$treatment, scale = "center")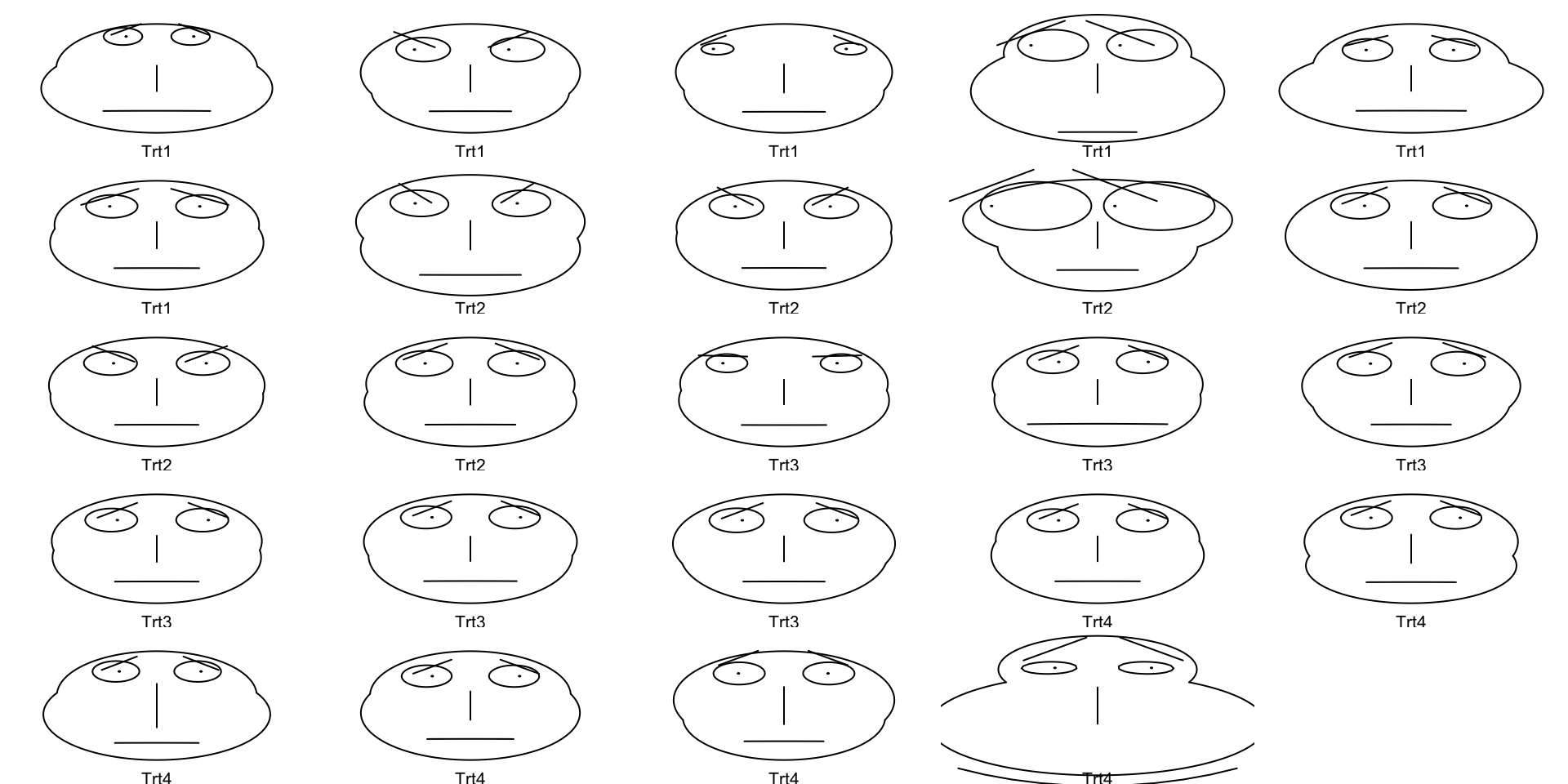
Star Plots
- Perhaps most usefully, you can just make “star plots” to check multivariate data
# Create star plots
graphics::stars(x = varespec, labels = lichen_df$treatment, key.loc = c(16, 9))
Principal Components Ordination
# With that done, we can make a graph of that information!
plot(x = lich_pc$x[,1], y = lich_pc$x[,2], pch = 20,
## And do some fancy axis labels to get 'variation explained' in the plot
xlab = paste0("PC1 (", (lich_pc_smry$importance[2, 1] * 100), " % variation explained)"),
ylab = paste0("PC2 (", (lich_pc_smry$importance[2, 2] * 100), " % variation explained)"))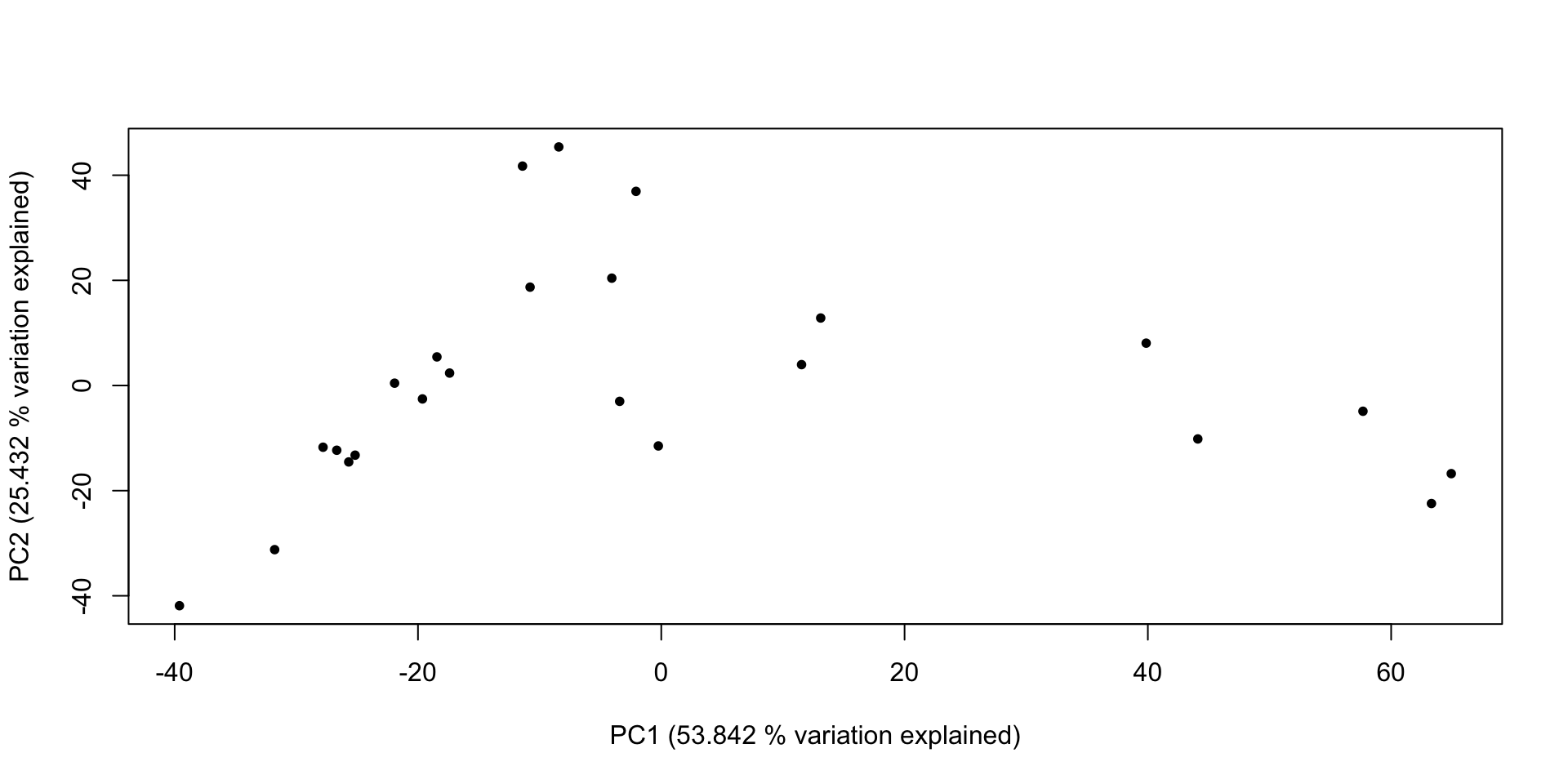
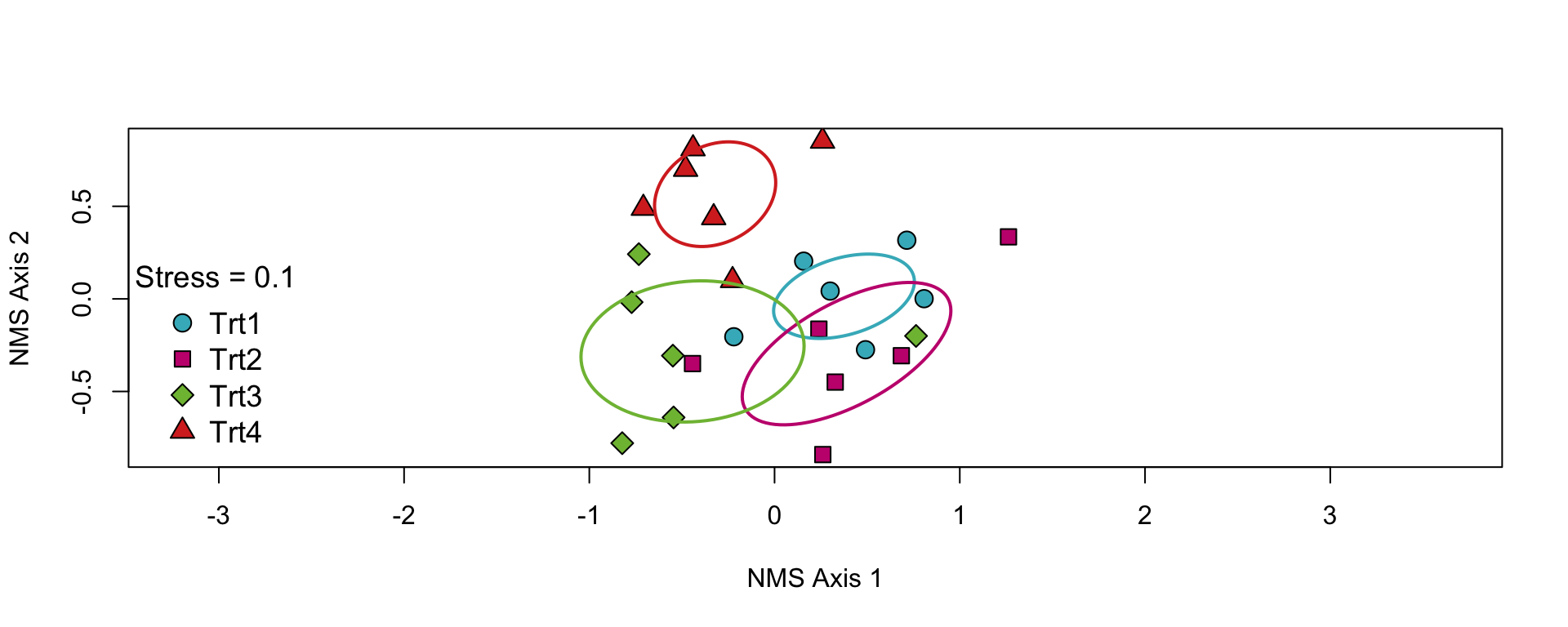
NMS Ordination
- Fortunately, we can use a nice ordination function from the
supportRpackage to make the graph
# Create NMS ordination
supportR::nms_ord(mod = lich_mds, groupcol = lichen_df$treatment)